[Home-K8S] #22 FluxCD 계층과 분리 / 다중 클러스터 리소스 공유와 설정 분리
FluxCD - yaml 앞서 fluxcd 를 이용해서 helm chart 를 구성했습니다. 그 외에 일반적인 yaml

![[AI] sLLM을 위한 모델 서빙](/content/images/2025/07/------1-1.png)
개인이 LLM을 서빙하는 것은 비용이 매우 많이 듭니다. 뭐 느려도 사용만 하겠다고 CPU로 연산하면 사용 가능하겠지만, 그것도 쉽진 않죠.
Deepseek-R1이 처음 나왔을 때 누가 맥미니를 최대 메모리로 6대(64GB x 6)를 사는 게 가장 저렴한 서빙 방식이라고 그랬죠.
하지만 양자화를 하거나 매개변수가 적은 모델들은 가능합니다. 쉽게 올리는 방법도 나왔죠.
기업이 아닌 이상 개인이 Serve할 때 UI보다는 API를 사용하기 위함이 더 클 겁니다. API가 활용성이 더 크고 사용할 방법이 더 많은 것도 있지만 가장 큰 문제는 비용 때문이죠.
UI는 무료로 또는 적은 결제로 많은 사용량을 제공해 주는게 많지만, API는 무료를 찾아보기 힘들 뿐더러 상대적으로 비싸거든요.

아무래도 가장 사용하기 편하고 유명한 방법은 Ollama를 이용한 방법입니다.
설치만 하면 바로 사용할 수 있습니다.
https://ollama.com/download
위에서 ollama를 다운받고 경로만 설정 해주면 됩니다.
리눅스는 좀 더 편하죠.
curl -fsSL https://ollama.com/install.sh | sh설치가 완료 되면 터미널에 들어가서 모델을 다운로드 받으시면 됩니다.
ollama serve
ollama pull gemma2'ollama run gemma2' 로 직접 터미널에서 사용해도 되지만, API로 사용하면 됩니다.
curl -X POST http://localhost:11434/api/chat -d '{"model":"llama3.1:8b","messages":[{"role":"user","content":"why is the sky blue?"}]}ollama에서 사용할 수 있는 모델은 ollama 홈페이지에서 찾아볼 수 있습니다.
기본적으로 모든 모델이 4비트 양자화 되어서 제공됩니다.
ollama에서는 원래 GGUF 모델을 사용할 수 없었는데, 최근에 모델 파일을 다운 받아 실행하는 기능이 추가되었다고 합니다.
LLM을 개인적으로 사용하는 경우에는 좀 느려도 되고, 요청이 많지도 않습니다.
하지만 LLM을 이용한 서비스를 구성했을 때, 그리고 사용자의 입력이 많아지게 되면 사용성이 매우 떨어지게 됩니다.
최적화를 하려면 동작 방식을 알아야 하겠죠.
LLM은 1토큰씩 생성합니다. 생성된 토큰을 앞의 문장에 합쳐서 또 다음에 올 토큰을 생성합니다.
Autoregressive 한 방식으로 생성하기 때문에, 출력이 긴 경우에 상당한 시간이 걸립니다. 많은 사람들이 동시에 사용한다면 정말 느리겠죠.
많은 요청을 빠르게 처리하기위해 추론 최적화가 필요합니다.
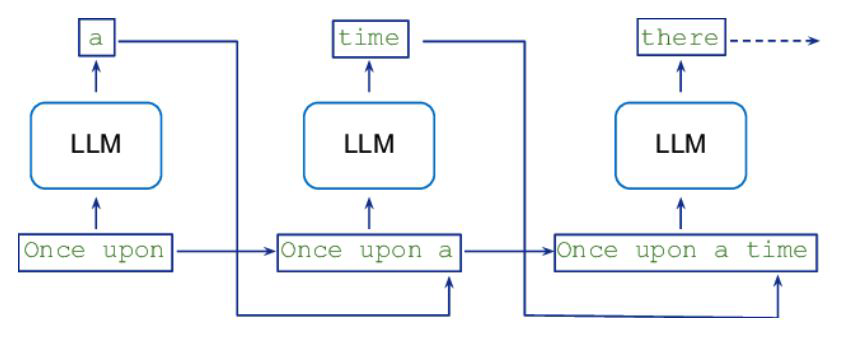
LLM이 아니라 다른 ML도 배치를 많이 사용하죠. 여러 개의 추론 요청을 동시에 처리하는 것을 말합니다.
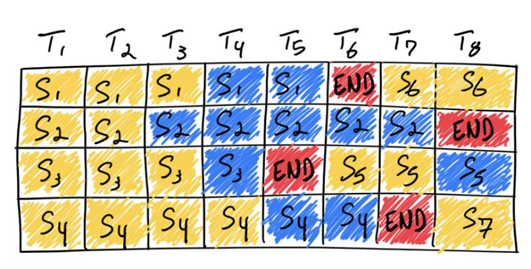
이걸 직접 개발한다고 생각하면 난이도가 확 올라가긴 하네요. 분산 GPU도 아니고 커널부터 만져야 겠어요.
Autoregressive하게 토큰을 생성하다보니 한 주제에 대해 토큰을 생성할 때 계산한 부분과 중복해서 계산하는 부분이 있습니다.
이 부분을 저장해 두었다가 사용하는 방법입니다.
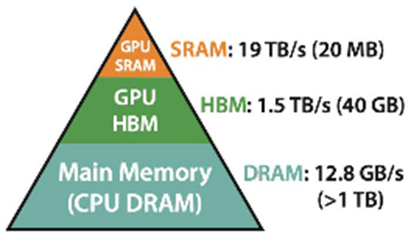
CPU의 캐시처럼 GPU의 SRAM은 연산이 매우 빠르지만 용량이 작습니다.
연산에서 데이터를 읽고 쓰는 시간이 가장 오래걸리는 과정이므로,
블럭단위로 연산해서 SRAM과 HBM이 값을 주고 받는 횟수를 최대한 줄이는 방법(Kernel Fusion)입니다.
vLLM은 이러한 최적화 방식들을 편하게 설정할 수 있게 해주는 라이브러리입니다.
기본적으로 여러 prompts를 동시에 처리하는 코드입니다.
from vllm import LLM, SamplingParams
prompts = [
"Hello, my name is",
"The president of the United States is",
"The capital of France is",
"The future of AI is",
]
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
llm = LLM(model="facebook/opt-125m", gpu_memory_utilization=0.8)
outputs = llm.generate(prompts, sampling_params)
# Print the outputs.
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
Comments