[Home-K8S] #22 FluxCD 계층과 분리 / 다중 클러스터 리소스 공유와 설정 분리
FluxCD - yaml 앞서 fluxcd 를 이용해서 helm chart 를 구성했습니다. 그 외에 일반적인 yaml

기존에는 가장 기본적인 오픈소스 모니터링 시스템 (prometheus + grafana, loki + promtail) 을 구성해서 대시보드와 알람을 구성했습니다.
구성을 하면서도 모니터링의 필요성에 대해서 의문을 가지긴 했지만, 구성을 하고 나니까 잡아먹는 리소스가 생각보다 더 많았습니다.
하드웨어 리소스도 그렇지만 prometheus stack 의 버전 업그레이드가 1주에 2~3개씩 나오는 것도 귀찮은 일 중에 하나였습니다.
모니터링을 뺄 생각도 있었는데, Public Cloud 를 k8s와 연동하면서 사용하고 싶었던 것 중에 하나가 모니터링 서비스 였습니다.
미리 말씀드리면 OCI-ONM 은 Oracle Instance 위에서 정상적으로 작동합니다.
일반적으로는 on-prem 에서 사용하기 위한 용도는 아닙니다.
가능/불가능을 취사선택하는 gpt 의 말을 믿고 시작했습니다.
일단 위 chart 를 이용해서 oci-onm 을 구성하게 되면 권한이 부족하다는 log가 나옵니다. log 는 잘 가져오는 것 같은데 다른 metric 이나 정보가 보이지 않습니다.
oracle cloud 를 사용하는 가장 큰 이유는 4코어 24GB 의 무료 인스턴스를 사용할 수 있기 때문입니다. 저는 이 인스턴스를 worker node 로 사용하고 싶었고, phoenix 서버에 생성해서 vpn으로 연결했습니다. (미국 vpn 으로 사용하기 싶어서 phoenix 에 구성했습니다.)
해당 worker node 에 oci-onm을 고정해 놓으면 정상적으로 작동할 것으로 보았습니다.
Oracle Cloud 에 ARM 으로 Talos Linux 를 구성하는 것은 성공했는데 계속 연결이 안되어서 gpt 를 추궁해보니 지연시간(150ms)이 너무 길어서 안되는 것을 알았습니다.
(etcd Heartbeat Interval 이 100ms 가 권장이고 Talos 가 기본적으로 50 정도로 설정되어 있습니다.) https://etcd.io/docs/v3.3/tuning/
일본 정도면 가능할 것으로 보이는데 괜히 phoenix 로 설정해서 worker node 가 아닌 그냥 서버로 사용 중입니다.
1안을 실패하여서 모든 트래픽을 직접 vpn 을 통해 보내주는 방법을 사용했습니다.
oci-onm chart 를 열어서 사용하는 도메인을 확인해보면 3가지가 있습니다.
telemetry-ingestion.us-phoenix-1.oraclecloud.com
objectstorage.us-phoenix-1.oraclecloud.com
telemetry.us-phoenix-1.oraclecloud.com1안 처럼 worker node 가 있다면 egress gateway 를 사용하면 되지만 그러지 못하므로 하나하나 넣어줘야 합니다.
cron 으로 매번 해당 ip 를 확인한 후에 업데이트 해주는 방법도 있고 넓은 대역대로 제공해 주는 방법도 있습니다.
홈랩에서 모니터링 구성하는 것도 사실 불필요하다고 생각합니다.
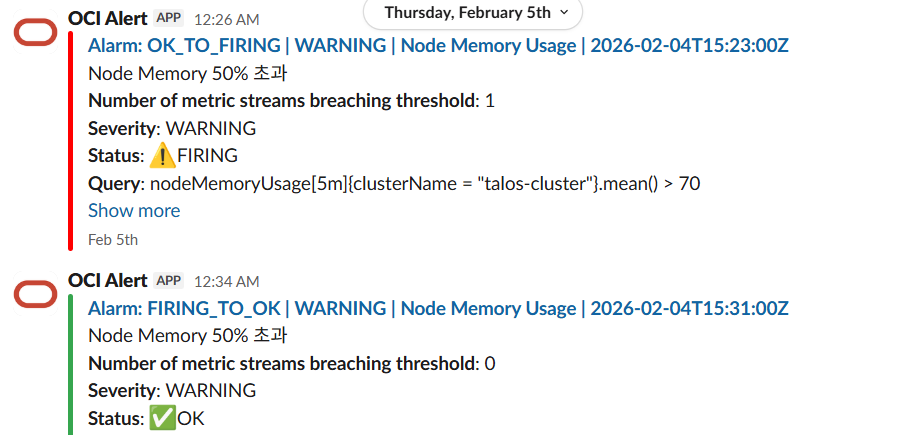
결국 기존의 promethus stack + loki + promtail 은 전부 빼내고 oracle cloud 로 전환 완료 했습니다. oracle cloud 안에서 사용하는 것처럼 완벽하게 기능하는 것은 아니지만, 대시보드도 편하게 생성하고 알람도 잘 오는 것으로 만족합니다.
Comments