[Home-K8S] #22 FluxCD 계층과 분리 / 다중 클러스터 리소스 공유와 설정 분리
FluxCD - yaml 앞서 fluxcd 를 이용해서 helm chart 를 구성했습니다. 그 외에 일반적인 yaml

![[AI] sLLM을 위한 모델 경량화](/content/images/2025/07/------1.png)
수백억~수천억개의 매개변수를 가지는 LLM과 달리, 수백만~수십억개의 적은 매개변수를 가지는 LLM.
모델의 크기가 작아, 컴퓨팅 리소스가 적어도 사용할 수 있습니다.
컴퓨팅이 적고 에너지 소모도 적어 모바일, 노트북 등에서도 활용할 수 있습니다.
성능은 LLM에 비해 부족하지만, 최적화를 통해 특정 분야에서는 LLM과 유사한 성능을 낼 수 있습니다.
적은 자원을 사용하는 sLLM을 더 효율적으로 사용하기 위해 모델 경량화를 합니다.
모델의 크기와 계산량을 줄이는 과정으로 성능을 손상시키지 않으면서 효율적으로 만드는 것을 목표로 합니다.
양자화가 가장 많이 사용되고 있는 방법이지요. 현재 딥러닝에서는 FP32를 가장 많이 사용하고 있습니다. 더 세밀한 FP64가 있는데 FP32를 사용하는 이유는 성능의 차이가 많이 나지 않아서 입니다.
FP64가 메모리는 배로 사용하고 속도도 느린데, FP32에 비해 성능의 차이가 거의 없습니다.
반대로 FP32를 줄이면 어떻게 될까요?
FP16 / BF16 / TF32 은 많이 사용되고 있습니다. 성능이 더 올라간다는 말도 있구요. 오버플로우 문제가 있긴 한데, AMP로 해결 가능합니다.
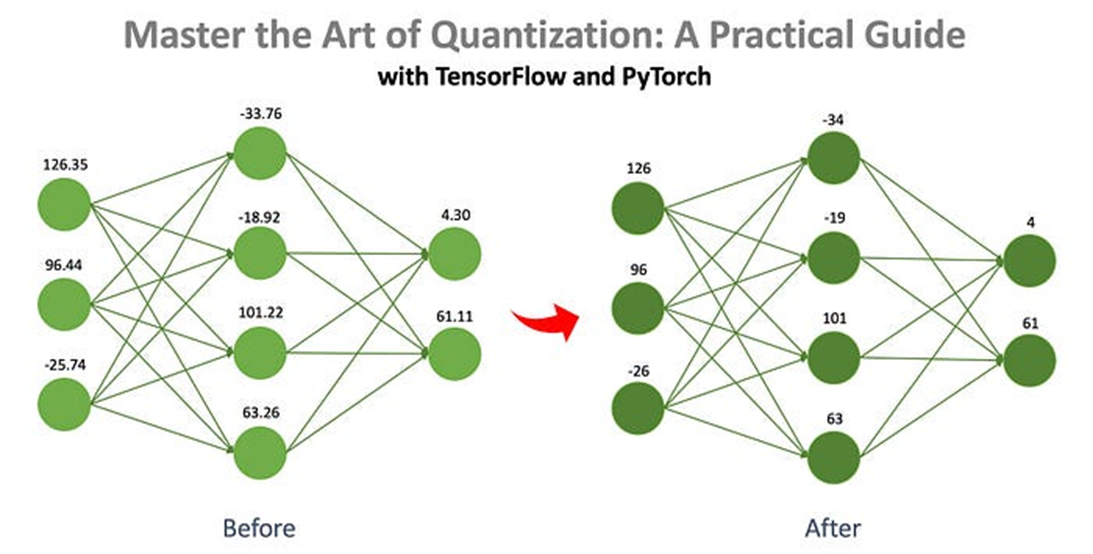
아날로그 값을 이산적인 디지털 값으로 표현하는 양자화처럼 모델의 정밀도를 낮춰 메모리와 연산 효율을 증가시키는 방법을 양자화라고 합니다.
앞 뒤를 버리는 방법입니다. 그냥 Type Casting이죠.
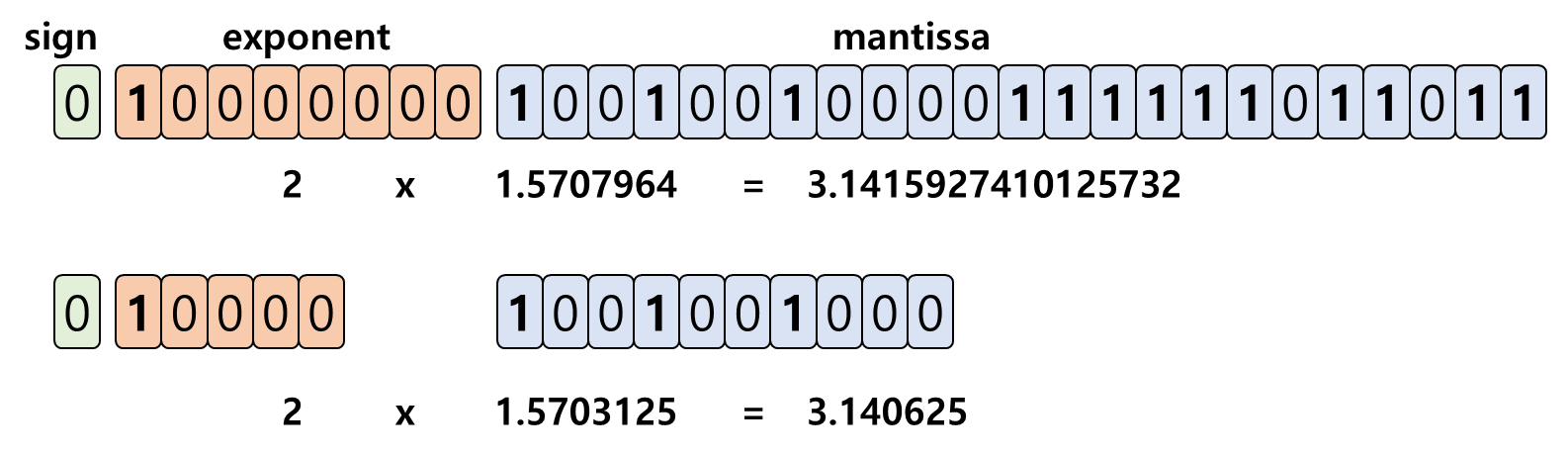
모델 내 최대 절댓값n만 찾아 양자화 계수를 매핑하는 방법입니다.
(모델 / n * 계수)
범위에 모여있는 경우 효율적이고, 최소를 생각 안하다 보니 비대칭적 분포를 이루고 있는 경우 잘 안됩니다.
def absmax_quantize(X):
# 스케일(양자화 계수) 계산
scale = 127 / torch.max(torch.abs(X))
# 양자화
X_quant = (scale * X).round()
# 역양자화
X_dequant = X_quant / scale
return X_quant.to(torch.int8), X_dequant모델 내 최소값도 찾아서 매핑합니다.
최소값이 음수이므로 zero point 값이 필요해 zero-point입니다.
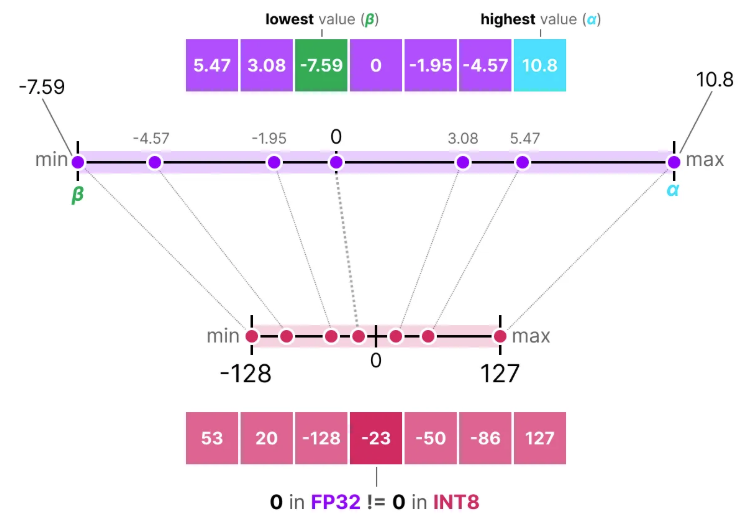
def zeropoint_quantize(X):
# 범위 계산
x_range = torch.max(X) - torch.min(X)
x_range = 1 if x_range == 0 else x_range # Division error 방지
# 스케일 계산
scale = 255 / x_range
# zero point 계산
zeropoint = (-scale * torch.min(X) - 128).round()
# 양자화
X_quant = torch.clip((X * scale + zeropoint).round(), -128, 127)
# 역양자화
X_dequant = (X_quant - zeropoint) / scale
return X_quant.to(torch.int8), X_dequantPTQ는 이미 훈련된 모델에 양자화를 적용하는 방식
QAT는 훈련 단계부터 양자화를 적용하는 방식
모델의 일부에 양자화를 먼저 적용하고, 오차를 계산해서 다음 부분에 적용하는 방식입니다.
모델 앞부분의 레이어를 양자화 한 뒤, 데이셋을 사용해 봅니다. 원본과의 오차를 가지고 다음 레이어를 순차적으로 양자화 합니다.
일반적으로 int4 타입으로 양자화를 진행합니다.
from auto_gptq import AutoGPTQForCausalLM, BaseQuantizeConfig
import torch
from transformers import AutoTokenizer
# Define base model and output directory
model_id = "gpt2"
out_dir = model_id + "-GPTQ"
quantize_config = BaseQuantizeConfig(
bits=4, #양자화 비트 수
group_size=128, #가중치 그룹 크기
damp_percent=0.01, #damp_percent. 변경X
desc_act=False,
)
model = AutoGPTQForCausalLM.from_pretrained(model_id, quantize_config)
tokenizer = AutoTokenizer.from_pretrained(model_id)
examples_ids = [ # x토큰화된 예제 {'input_ids': , 'attention_mask': }]
# Quantize with GPTQ
model.quantize(
examples_ids,
batch_size=1,
use_triton=True,
)
# Save model and tokenizer
model.save_quantized(out_dir, use_safetensors=True)
tokenizer.save_pretrained(out_dir)CPU 추론에 최적화된 양자화 라이브러리로, 중요도에 따라 양자화의 강도를 다르게 합니다. (k-quant system)
중요한 가중치는 보호하고 덜 중요한 가중치만 적극적으로 양자화
모델 중간에 양자화 및 역양자화 모듈을 삽입해서 양자화의 정보 손실을 모델 학습시의 목표에 추가합니다.
이번에 MS 에서 1.58bit(-1,0,1)를 사용한 모델을 발표했죠. 행렬 연산이 필요 없어짐에 따라 CPU 연산으로 상당한 성능을 낸 모델입니다.
1.58bit는 "이것도 가능하다"라는 느낌이라 타협해서 2/4bit 정도로 하면 꽤 좋을 것 같습니다.
경량화로 모델을 줄이는 방법은 기계적입니다. 각 매개변수의 역할을 고려할 수는 없죠.
그래서 sLLM을 다시 고성능화를 하기 위해 fine-tuning을 적용하는 경우가 많습니다.
큰 모델(LLM) 에서 필요한 정보를 '증류'해서 sLLM에 학습을 시킵니다.
CoT 도 수행할 수 있게 된다고도 하는데, 그래도 한계는 있습니다.
모델 전체 대신 일부분만 학습시키는 방법

가장 먼저 적용된 PEFT 기술 중 하나로 모델의 각 트랜스포머 계층에 학습 가능한 작업별 매개변수 몇 개를 삽입하는 방법
원본 모델은 가만히 놔두고 아주 작은 어뎁터 모듈을 모델 옆에 붙이고 학습.
LLM 뿐만 아니라 이미지를 생성하는 Generative Model에서도 사용됩니다.
LoRA 보다 적은 자원을 위해 모델을 먼저 양자화 한 뒤 LoRA를 시행
NF4 quantization (모델의 가중치 정규화 > 4bit float 매핑)
Double quantization (역양자화 상수를 양자화해서 저장)
Prefix 튜닝 - NLG를 위해 특수 제작된 조정
프롬프트 튜닝 - 입력/학습 데이터에 맞춤형 프롬프트를 주입.
P-튜닝 - NLU를 위해 설계된 프롬프트 튜닝의 변형
from IPython.display import clear_output, display, HTML
def show_progress(percentage, activity, show=True):
clear_output(wait=True)
if show:
display(HTML(f'''<div style="position:fixed;top:0;left:0;width:100%;background-color:#f0f0f0;padding:10px;text-align:center;">
<p>{activity}</p>
<progress style="width:100%; {"" if show else "display: none"}"></progress></div>
'''))
hf_model_name = "1bitLLM/bitnet_b1_58-large" # @param ["1bitLLM/bitnet_b1_58-large","1bitLLM/bitnet_b1_58-3B","HF1BitLLM/Llama3-8B-1.58-100B-tokens"]
model_quant_type = "tl2" # @param ["tl2","tl1"]
# Installing key env
!bash -c "$(wget -O - https://apt.llvm.org/llvm.sh)"
show_progress(0, "Cloning BitNet...")
!git clone --recursive https://github.com/microsoft/BitNet.git
%cd BitNet
# Pip installation
show_progress(20, "Upgrading pip and installing requirements.txt...")
!pip install --upgrade pip >> log.bitnet
!pip install -r requirements.txt >> log.bitnet
show_progress(50, f"Downloading and converting {hf_model_name} model to gguf...")
!python3 setup_env.py --hf-repo {hf_model_name} -q {model_quant_type} >> log.bitnet
show_progress(50, f"The model {hf_model_name} is Ready for inference", False)
print("Downloading Completed Successful")
# @title # bitnet 실험해보기
prompt = "My dream is" # @param {"type":"string"}
token_number = 100 # @param {"type":"number","placeholder":"how many token to be generated"}
show_progress(100, f"Complete", False)
model_selected = hf_model_name.split('/')[1]
converted_model_path = f"models/{model_selected}/ggml-model-{model_quant_type}.gguf"
# print(converted_model_path)
command = f'run_inference.py -m {converted_model_path} -p "{prompt}" -n {token_number} -temp 7'
!python3 {command}
Comments